

Pour parler d'écologie dans l'intelligence artificielle il faut aussi parler technique avec des arguments que les DSI et développeurs ne pourront qu'apprécier.
Je reprends ci dessous en intégralité la tradution de l'article du cofondateur de ThirdAI, Shrivastava Anshumali, sur un sujet important pour la mise en production des IA. ThirdAI et MoniA ont intégré cette solution en partenariat exclusif dans la distibution des produits en France pour NeuralDB Entreprise. MoniA utilise cette technologie d'avant garde pour toutes les solutions IA.
Modèles de base de ThirdAI avec une latence limitée pour les environnements de production à ultra-haute vitesse
Dans les environnements de production distribués d'aujourd'hui, qui évoluent rapidement, la prise de décision en temps réel s'appuie de plus en plus sur des modèles PNL fondamentaux pour des prédictions précises. Ces environnements exigent une vitesse ultra élevée et des contraintes de latence strictes, nécessitant souvent des temps de réponse inférieurs à 10 millisecondes sur un seul cœur de processeur, même avec des tailles d'entrée extrêmement fluctuantes. De plus, les pipelines d’IA doivent souvent fonctionner dans des environnements distribués hétérogènes où les ressources informatiques avancées telles que les GPU peuvent ne pas être disponibles.
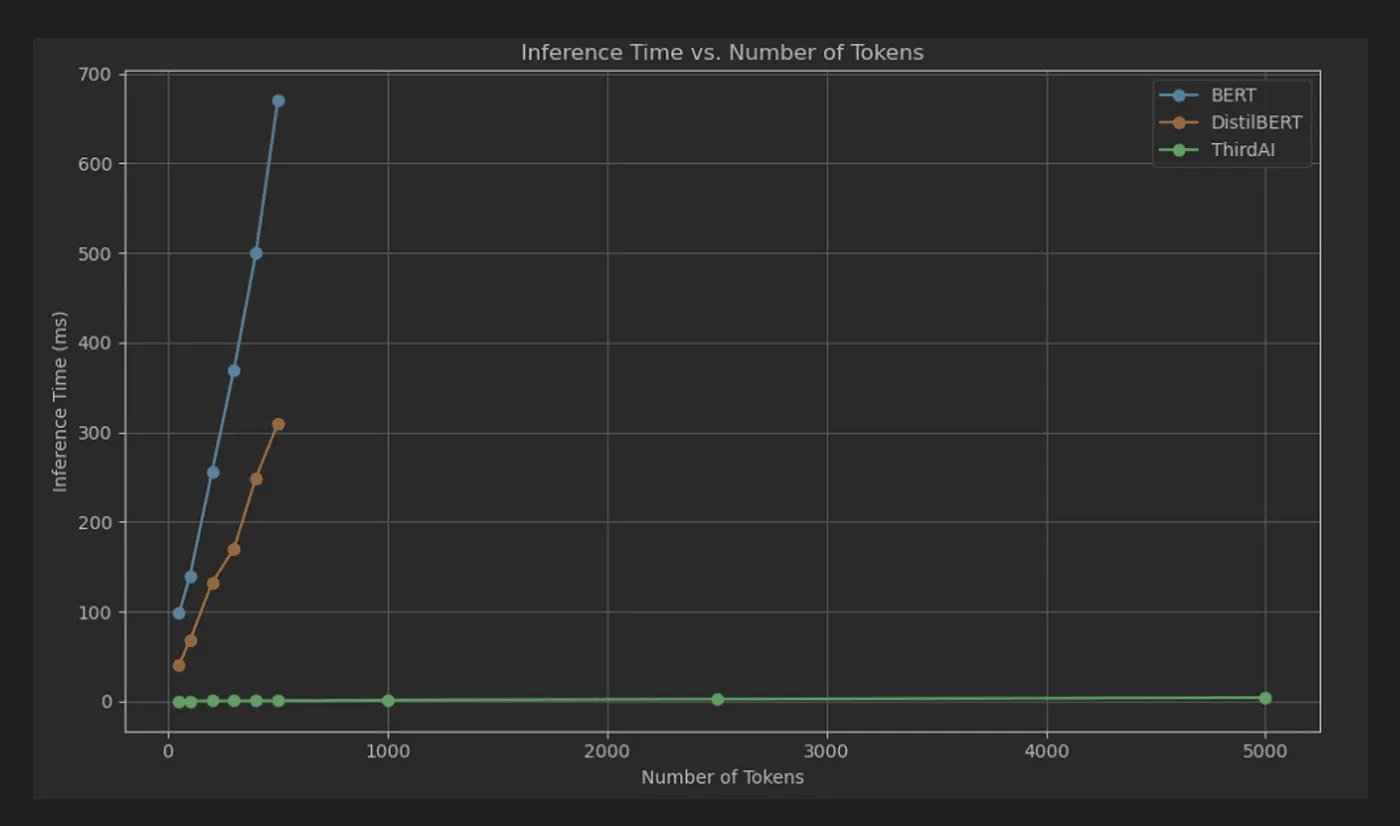
- Le graphique ci dessus montra le latence de classification de bout en bout (millisecondes) sur un seul cœur de processeur de BERT, DistilBERT et ThirdAI. L'axe des X représente le nombre de jetons dont la production peut varier de quelques à plusieurs milliers. La latence de ThirdAI est toujours inférieure à 10 ms. Tous les modèles sont réglés avec la même précision.
ThirdAI relève le défi de front. Nous sommes ravis de présenter nos modèles fondamentaux pré-entraînés spécialisés et spécialement conçus. Ces modèles sont conçus pour fournir des prédictions précises avec une latence de bout en bout inférieure à 10 millisecondes sur un seul cœur de processeur . Remarquablement, même lors du traitement de jusqu’à 5 000 tokens, nos modèles maintiennent une latence inférieure à 10 ms. Les performances de ces modèles lors de l'inférence et du réglage fin restent cohérentes, quelle que soit l'hétérogénéité du processeur.
Pour les développeurs cherchant à exploiter la puissance de notre technologie, nous fournissons un script simple pour affiner le modèle fondamental de ThirdAI sur n'importe quel ensemble de données de classification supervisée multilingue. Cela permet une prédiction ultra-rapide avec des niveaux de précision comparables à ceux des modèles fondamentaux bien connus. Par exemple, lors d'une tâche de classification d'intention avec le benchmark Curekart , le script atteint une précision de classification de 83,87 %, correspondant à la précision d'un modèle BERT affiné sur le même ensemble de données.
Pourquoi les modèles de Hugging Face ne répondent-ils pas aux exigences de latence ?
Notre analyse (la figure ci-dessus) montre que même avec seulement 512 jetons (limite de contexte), la latence du BERT multilingue — un modèle largement utilisé pour la classification NLP — atteint 700 ms. À l'opposé, le modèle de ThirdAI reste systématiquement inférieur à 5 ms de latence, même avec 5 000 jetons, soit 10 fois plus de taille d'entrée et 140 fois plus rapide que BERT.
Même les tentatives visant à réduire la latence avec des modèles comme DistillBERT se sont révélées insuffisantes. DistillBERT ne réduit la latence qu'à environ 350 ms avec 512 jetons sur un seul cœur, ce qui est encore beaucoup trop lent pour de nombreuses applications en temps réel. Voir une étude de cas Wayfair validant la nécessité de modèles à latence beaucoup plus faible.
La différence ThirdAI : pourquoi avons-nous besoin d’une nouvelle pile de développement ?
De toute évidence, la latence des modèles fondamentaux actuels est plus de 100 fois inférieure aux exigences de production. Les approches existantes telles que l'élagage, la distillation et la quantification sont des techniques de post-traitement appliquées à un modèle existant et sont donc limitées dans la mesure dans laquelle elles peuvent améliorer drastiquement les performances - en général, le meilleur scénario est une amélioration de 5 fois. De plus, comme les modèles sont censés être ajustés régulièrement, les performances peuvent fluctuer considérablement si les pondérations des modèles fondamentaux sont modifiées.
Les modèles de base construits à l'aide de la pile logicielle ThirdAI suivent une philosophie de conception complètement différente. Ils sont conçus dès le départ pour être formés et déduits dans le cadre d'un budget donné sur un processeur monocœur, en utilisant la parcimonie dynamique . La latence d'inférence est intentionnellement conçue pour être minimale. Même pendant l'entraînement et le réglage fin, la descente de gradient ajuste les poids afin que le modèle dynamiquement (contextuellement) clairsemé atteigne une précision optimale. Le cycle complet du modèle d'IA, y compris la pré-formation, le réglage fin et le déploiement, ne nécessite que quelques cœurs de processeur de base. Cela simplifie considérablement le pipeline complet, tant du point de vue logiciel que matériel.
Conclusion
Grâce à ses innovations, ThirdAI établit de nouvelles normes en matière de latence et d'efficacité dans les modèles d'IA, garantissant que la prise de décision en temps réel dans les environnements basés sur l'IA est à la fois rapide et fiable.
MoniA et ACTIV'HA intégrent déjà cette technologie et distribuent NeuralDB en France pour les entreprises intéressées.