

Vous avez des boîtiers CPU en réserve ? Cerveau de tout système informatique, la CPU (Central Processing Unit) vous permet de créer et de déployer des applications d’IA générative à grande échelle ! Notre chatbot conversationnel MonIA se base sur cette puissance de calcul exceptionnelle pour traiter de grandes quantités de données et générer des réponses précises et pertinentes en temps réel.
Pour bien comprendre son fonctionnement, nous présentons dans cet article une étude de cas menée par notre partenaire ThirdAI. Cette startup d'intelligence artificielle vise à rendre les modèles de langage de grande taille (LLM) et d'autres technologies d'IA de pointe accessibles à tous. L’entreprise a développé NeuralDB, une solution logicielle complète pour la recherche générative à grande échelle. Elle a permis de construire le plus grand système de questions-réponses à réglage et mise à l’échelle automatiques, incorporant plus de 120 millions d’extraits de texte d’articles PubMed. Cette réalisation a été effectuée en utilisant seulement 6 processeurs AMD Bergamo, sans avoir besoin de GPU, et le tout en un week-end. Après sa configuration initiale, le système peut être déployé efficacement sur une seule AMD Milan Box avec une latence de 10 requêtes par seconde. De plus, le système déployé améliore continuellement ses réponses grâce à l’utilisation et au retour d’information implicite au fil du temps par le réglage en ligne, sans nécessiter aucune modification d’ingénierie ou de code.
Objectif : Développer un système de questions-réponses médicales (RAG) orienté vers l’utilisateur et auto-améliorant, basé sur 120 millions de blocs de texte de PubMed
PubMed a mis à disposition 35 millions d’articles. Après avoir subi un traitement standard, ils se composent de 120 millions de morceaux de texte. Ces derniers constituent la base d’un chabot de questions-réponses conçu pour fournir des informations précises et fiables fondées sur des citations PubMed, une source de confiance de la communauté médicale. L’objectif est que ce système s’ajuste automatiquement et améliore ses performances au fil du temps, à l’instar de Google Search.
Par exemple, si les utilisateurs recherchent systématiquement « rhume et toux » et montrent une préférence pour les réponses liées au « Covid » par rapport à celles liées à la « grippe », le système apprendra de ces modèles grâce à un retour d’information implicite de l’utilisation naturelle, éliminant ainsi le besoin de mises à jour manuelles.
ThirdAI utilise NeuralDB pour mettre en œuvre la génération augmentée de récupération (RAG) pour la génération contextuelle. Elle met l’accent sur la recherche en ligne ajustable pour faciliter l’auto-optimisation continue.
Ajustement des modèles génératifs vs ajustement des modèles de recherche
Le réglage fin d’un modèle génératif est une tâche délicate et complexe. ChatGPT peut être librement utilisé pour la génération. Toutefois, vouloir affiner ChatGPT en mettant à jour ses poids peut introduire de nombreuses difficultés dans la gestion du modèle GenAI. Une alternative viable consiste à affiner le composant de récupération à l’aide des API NeuralDB simples. En personnalisant le système de recherche, ThirdAi peut ainsi adapter automatiquement le processus de génération en ajustant le contexte de chaque requête. Cette méthode s’avère souvent adéquate pour personnaliser les réponses générées sans qu’il soit nécessaire de modifier directement le modèle génératif.
Présentation de NeuralDB : une bibliothèque logicielle à mise à l’échelle automatique avec réglage en ligne à grande échelle
ThirdAI a déployé NeuralDB Enterprise sur 6 machines AMD EPYC 9754. Chacune est dotée de 128 cœurs, acquises grâce à leur collaboration avec AMD. À l’aide d’un script simple nécessitant un seul appel de fonction - et sans réglage manuel ni effort d’ingénierie - la planification, la parallélisation et la surveillance des tâches se font sans effort. NeuralDB automatise la lecture parallèle des données, le pré-entraînement spécifique à un domaine de ses modèles et l’indexation ultérieure dans une base de données de clés locale. Le logiciel réalise ainsi l’ensemble de la configuration en seulement 60 heures. Cette efficacité bénéficie du parallélisme des données et est conçue pour une mise à l’échelle horizontale. Par exemple, l’extension de l’installation de 6 à 12 processeurs pourrait réduire de moitié le temps d’installation à 30 heures.
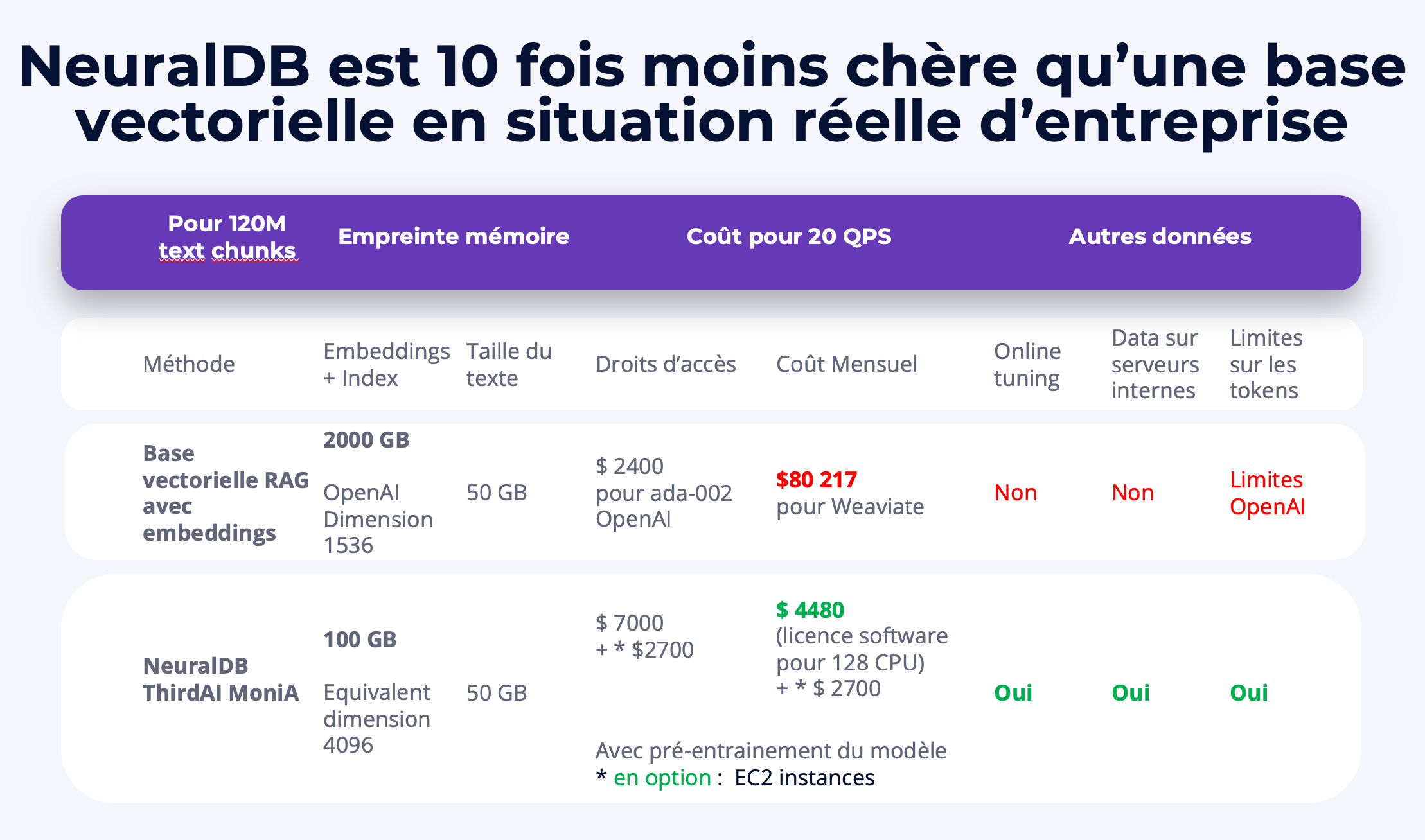
Une fois le pré-entraînement et l'indexation terminés, le système est prêt à être déployé en un seul clic, ce qui témoigne de sa remarquable légèreté. Un seul serveur AMD Milan à double socket 64 cœurs suffit amplement pour déployer ce vaste système de chatbot. Contrairement aux approches traditionnelles d'intégration et de base de données vectorielles, qui peuvent nécessiter la gestion de 2 téraoctets d'index (voir tableau), la technologie innovante de NeuralDB n'a besoin que d'un index de 100 Go. Cela rend une seule unité centrale plus que suffisante pour l'hébergement à grande échelle. Le modèle hébergé est accessible ici.
NeuralDB facilite l’amélioration continue grâce aux retours d’information implicites et explicites des utilisateurs. Il répond aux requêtes des utilisateurs avec des citations, diversifiées pour assurer une large couverture semblable à celle des moteurs de recherche commerciaux. Les utilisateurs améliorent la précision du système en approuvant des extraits utiles ou en reliant les questions à des informations spécifiques ou à des réponses partielles. De plus, le système recueille le retour d’information implicite par le biais d’une utilisation standard. Des mises à jour régulières, éclairées par ces mécanismes de feedback, le transforment en un système de questions-réponses médicales RAG en constante évolution. NeuralDB devient ainsi le premier chatbot médical spécialement conçu pour augmenter sa pertinence et son utilité grâce à des interactions naturelles avec les utilisateurs, parallèlement à la recherche Google.
Pourquoi pas les bases de données vectorielles habituelles : Embedding et VectorDB ?
Les approches RAG existantes posent des défis importants pour atteindre les objectifs de ThirdAI pour deux raisons principales :
- Coût prohibitif, mémoire et déplacement des données à l’échelle de 120 millions de blocs: dans la section suivante, nous détaillons le coût, l’encombrement de la mémoire et les exigences en matière de déplacement des données. La mémoire apparaît comme un goulot d’étranglement majeur à cette échelle. Pour environ 120 millions de blocs de texte, l’incorporation vectorielle (1 536 dimensions) et l’index lui-même occupent environ 2 To de stockage (1 To pour l’incorporation + 1 To pour l’index de recherche). Cela nécessite une gestion constante. En revanche, NeuralDB nécessite moins de 100 Go pour son index. Avec 50 Go de données, il rentre toujours dans les limites des boîtiers CPU de niveau serveur, tels que Milan.
- Manque d’adaptabilité à l’évolution constante (ou dérive du concept) dans l’intégration et VectorDB: toute modification du modèle d’incorporation nécessite une reconstruction complète des VectorDBs. Il n’est pas viable d’utiliser des intégrations obsolètes par rapport à des intégrations mises à jour. Par conséquent, le réglage en ligne n’est pas possible dans cet écosystème. Cela nécessite une surveillance continue et une équipe dédiée pour maintenir la qualité de la recherche en fonction du concept et de l'utilisation au fil du temps.
Analyse des coûts et des ressources
Les entreprises soucieuses de l’évolutivité donnent la priorité à la résidence des données, à la latence, à la haute disponibilité et à la facilité d’utilisation. À l’heure actuelle, de nombreux cas d’utilisation potentiels à grande échelle ne sont pas poursuivis en raison de préoccupations concernant la résidence des données. NeuralDB adopte une approche axée sur l’entreprise en matière de génération augmentée (RAG), conçue en tenant compte de ces priorités.
Pour illustrer son évolutivité et sa rentabilité, comparons NeuralDB à une solution d’entreprise populaire pour RAG : OpenAI Embedding combinée à Weaviate VectorDB. Cette solution est connue pour sa tarification transparente et sa haute disponibilité. La comparaison, détaillée ci-dessous et dans le tableau ci-joint, porte sur les points suivants :
- Latence d’interrogation cible: 20 qps (requêtes par seconde)
- Propriété souhaitable: Gestion de la dérive du concept au fil du temps
Option 1 : Intégration + VectorDB (ne peut pas tolérer de dérive) :
Coût pour 120 millions de vecteurs : 80 217,9 $ par mois, sur la base de 13 363,2 fois 6, en supposant une dimension de 1 536 (OpenAI Ada) et une disponibilité au niveau de l’entreprise, telle que calculée avec le calculateur de prix Weaviate. Le coût d’intégration est de 2 400 $ pour l’indexation avec OpenAI Ada-2. Le réglage fin à cette échelle est difficile et coûteux.
Surcharge de mémoire : environ 2 To au total. Les intégrations représentent environ 1 To (1536 x 120 millions ~ 200 milliards de flottants → 800 Go pour les intégrations). L’index nécessite 1 To supplémentaire. La gestion de ces 2 To de mémoire, en particulier leur chargement, peut affecter la latence. Tout réglage fin nécessite une mise à jour complète de l’intégration et de l’index. Les données ne comprennent que 50 Go de texte.
Option 2 : NeuralDB + MoniA (conçus pour l’échelle et la dérive constante) :
NeuralDB offre une solution simplifiée et uniquement logicielle. En utilisant les CPU existants, le coût du matériel est négligeable. Les frais d'abonnement au logiciel se limitent à un montant forfaitaire par cœur. En déployant NeuralDB Enterprise, vous pouvez transformer tous vos cœurs de processeurs en une infrastructure de recherche sémantique à la demande, tout en affectant les cœurs libres à d’autres tâches.
Pour calculer le coût total, même en utilisant la tarification EC2 premium, il existe de nombreuses options rentables pour les cœurs de CPU. Par exemple, 16 instances hpc6a.48xlarge (96 vCPU AMD EPYC) peuvent générer l’index sur 120 Mo en 60 heures environ. Avec un prix à la demande de 2,88 $/heure, le coût du matériel est approximativement de 2 700 $. L’abonnement au logiciel, à environ 2 cents par heure et par cœur pour 1 600 cœurs sur 60 heures, s’élève à environ 1980 $. Ainsi, l’ensemble de l’installation coûte environ 4 680 $ pour la construction de l’index.
Hébergement :
Après la création de l’index, une seule instance r7a.32xlarge (CPU AMD EPYC de 4e génération) peut prendre en charge une inférence de 20 QPS (requête par seconde). Cela entraîne un coût estimé à 3 224 $ (prix réservé) pour le matériel EC2 et à environ 4 480 € pour le logiciel pour 128 cœurs par mois. Ces coûts logiciels peuvent être encore réduits grâce à la tarification en gros des logiciels d’entreprise.
Frais de mémoire :
Les données représentent 50 Go, avec un index inférieur à 100 Go, incluant des modèles profonds à 10 milliards de paramètres. Notamment, NeuralDB n’utilise pas d’intégrations. Cela qui signifie que les 120 millions de blocs de texte sont traités par un réseau neuronal d’environ 10 milliards de paramètres, occupant moins de 40 Go pour les paramètres.
Défis en matière de questions-réponses médicales : problèmes de fiabilité et retour d’information limités des utilisateurs
Les chatbots médicaux, dont ChatGPT, offrent des réponses aux questions liées à la santé. Cependant, ces agents conversationnels font souvent l’objet d’un examen minutieux quant à la fiabilité de leurs sources. Bien que les bases de données comme PubMed fournissent des informations fiables, leur présentation n’est pas aussi conviviale que celle des chatbots.
Un problème important est que ni ChatGPT ni PubMed n’intègrent les feedbacks des utilisateurs dans leurs processus d’apprentissage. Par exemple, si les utilisateurs recherchent fréquemment « rhume et toux » et sélectionnent systématiquement les résultats liés à la COVID, un système efficace identifierait ces tendances. Il ajusterait ainsi ses réponses en conséquence. Le manque d’utilisation des « retours d’information implicites » dans les recherches actuelles de PubMed et les chatbots, tels que ChatGPT, diminue la satisfaction des utilisateurs. Le concept de feedback implicite, datant de plus de vingt ans, est le fondement de la plupart des moteurs de recherche commerciaux à succès. Il améliore quotidiennement l’expérience des utilisateurs. Pour en savoir plus sur le rôle des commentaires implicites dans les moteurs de recherche populaires, lisez notre article.